A Tragédia da Indexação de Dados na Polymarket
Resumo
Bem-vindo à série “Tragédia dos Comuns em Cripto” da GCC Research.
Nesta série, concentramos a nossa análise nos principais bens públicos do universo blockchain — pilares essenciais do ecossistema cripto que têm vindo a afastar-se dos valores de descentralização. Estes bens sustentam a Web3, mas enfrentam frequentemente falta de incentivos, desafios de governação e riscos de centralização. O desequilíbrio entre os ideais de descentralização e a redundância necessária para estabilidade real está, hoje, sob máxima pressão.
Este artigo destaca uma das aplicações mais notórias da rede Ethereum: a Polymarket e as respetivas soluções de indexação de dados. Desde o início do ano, polémicas — desde alegadas manipulações de oráculos associadas às probabilidades eleitorais de Trump, passando por apostas em terras raras ucranianas e previsões sobre a cor do fato de Zelensky — colocaram repetidamente a Polymarket sob os holofotes. O volume e a influência dos capitais em jogo tornam estas controvérsias incontornáveis.
Mas será que este “mercado de previsões descentralizado” atingiu a verdadeira descentralização onde mais importa — na camada de indexação de dados? Por que razão infraestruturas supostamente descentralizadas, como a The Graph, não correspondem às expetativas? O que deverá, afinal, constituir uma solução de indexação de dados públicos realmente viável e sustentável?
I. O Efeito Dominó de uma Paragem numa Plataforma Centralizada de Dados
Em julho de 2024, a Goldsky — fornecedora de infraestrutura de dados blockchain em tempo real para programadores Web3, com serviços de indexação, subgraphs e streaming — registou uma interrupção de seis horas. Este incidente derrubou uma parte substancial do ecossistema Ethereum: interfaces DeFi deixaram de exibir posições e saldos, mercados de previsões como Polymarket ficaram sem dados correctos e, para o utilizador, inúmeras aplicações deixaram de funcionar.
É precisamente para evitar situações destas que as aplicações descentralizadas existem. O design blockchain procura, em primeira linha, eliminar pontos únicos de falha. O episódio Goldsky revelou uma verdade incómoda: embora as blockchains sejam desenhadas para a descentralização, quase toda a infraestrutura que serve as aplicações on-chain permanece fortemente centralizada.
A raiz do problema está no facto de a indexação e consulta de dados blockchain serem bens públicos digitais — não-excludentes e não-rivais —, aos quais os utilizadores esperam ter acesso gratuito ou praticamente gratuito. Todavia, manter este tipo de infraestrutura obriga a investimento contínuo em hardware, armazenamento, largura de banda e engenharia. Sem um modelo de receitas sustentável, o setor tende para um resultado tipo “winner-takes-all”: se um fornecedor ganha vantagem em rapidez e capital, os programadores canalizam todas as suas solicitações para esse operador, criando um novo ponto único de dependência. Organizações como a Gitcoin têm chamado a atenção para o facto de a “infraestrutura open-source gerar milhares de milhões em valor, mas os seus criadores frequentemente não conseguem sequer pagar a própria casa”.
A mensagem é clara: o universo descentralizado precisa de respostas urgentes — financiamento de bens públicos, mecanismos de redistribuição de incentivos ou modelos auto-geridos pela comunidade — para diversificar a infraestrutura Web3 e evitar novas formas de concentração. Apelamos para que os programadores de DApps adotem estratégias local-first e para que as comunidades técnicas desenhem aplicações capazes de lidar de forma elegante com falhas na obtenção de dados — garantindo que os utilizadores possam continuar a interagir, mesmo com indexadores fora de serviço.
II. De Onde Vêm Realmente os Dados do Seu DApp?
Para perceber episódios como a interrupção Goldsky, é essencial analisar em detalhe como funcionam os DApps. A generalidade dos utilizadores conhece apenas duas camadas: o contrato on-chain e o frontend. Consultam normalmente o Etherscan para ver o estado das transações, usam o frontend para obter informação e executam contratos via interface. Mas, afinal, qual é a verdadeira origem dos dados apresentados no frontend?
O Papel Fundamental dos Serviços de Recuperação de Dados
Imagine que está a construir um protocolo de crédito que pretende mostrar posições, margens e dívidas dos utilizadores. Uma abordagem direta seria o frontend consultar estes dados diretamente à blockchain. Porém, a maioria dos contratos não permite consultar todas as posições de um endereço, mas apenas por ID de posição. Ou seja, para mostrar as posições de um utilizador, teria de percorrer todas as posições em aberto e filtrar manualmente as pertencentes ao mesmo — um processo equivalente a procurar manualmente entre milhões de registos contabilísticos. Embora tecnicamente possível, seria extremamente moroso e ineficaz. Na prática, mesmo com servidores backend, podem ser necessárias horas para que projetos DeFi de maior dimensão recuperem estes dados de um nó local.
É aqui que se torna decisiva a infraestrutura dedicada. Fornecedores como a Goldsky disponibilizam serviços de indexação de dados que aceleram o acesso de forma significativa. O diagrama seguinte mostra os tipos de dados que estas soluções tornam acessíveis às aplicações.

Alguns leitores perguntar-se-ão: não oferece a The Graph indexação descentralizada de dados para Ethereum? Como se compara com a Goldsky — e porque será que tantos projetos DeFi optam pela Goldsky em detrimento da The Graph?
Como se Integram The Graph, Goldsky e SubGraph
Para clarificar, distinguem-se os seguintes conceitos técnicos:
- SubGraph é um framework de desenvolvimento. Permite criar código para leitura e agregação de dados on-chain, a apresentar no frontend.
- The Graph é uma plataforma descentralizada de referência na recuperação de dados, criadora do framework SubGraph (baseado em AssemblyScript). Programadores utilizam o SubGraph para captar eventos de contratos e gravar os dados numa base de dados consultável via GraphQL ou SQL.
- Os operadores que executam SubGraphs são chamados operadores de SubGraph. Tanto The Graph como Goldsky servem de hosts para projetos SubGraph, dado que o código SubGraph tem de correr em servidores. Eis um excerto da documentação da Goldsky:
Porque existem múltiplos operadores SubGraph?
Porque o framework apenas define a extração e gravação de dados dos blocos, sem especificar o fluxo exato ou exportação dos dados. Cada operador implementa estas funções à sua maneira.
Os operadores podem aplicar alterações e otimizações específicas. A The Graph recorre atualmente ao Firehouse para indexação acelerada, enquanto o runtime central de SubGraph da Goldsky permanece fechado.
A The Graph opera como um hub descentralizado para operadores SubGraph. Por exemplo, o subgraph Uniswap v3 conta com múltiplos operadores, tornando a The Graph num verdadeiro marketplace coletivo onde developers submetem o código SubGraph e diversos operadores processam as consultas.
Modelo de Preços da Goldsky
Enquanto serviço centralizado SaaS, a Goldsky apresenta um modelo tradicional de pagamento por recursos. A maioria dos engenheiros conhece bem esta lógica. Eis o simulador de preços da Goldsky:
Modelo de Preços da The Graph
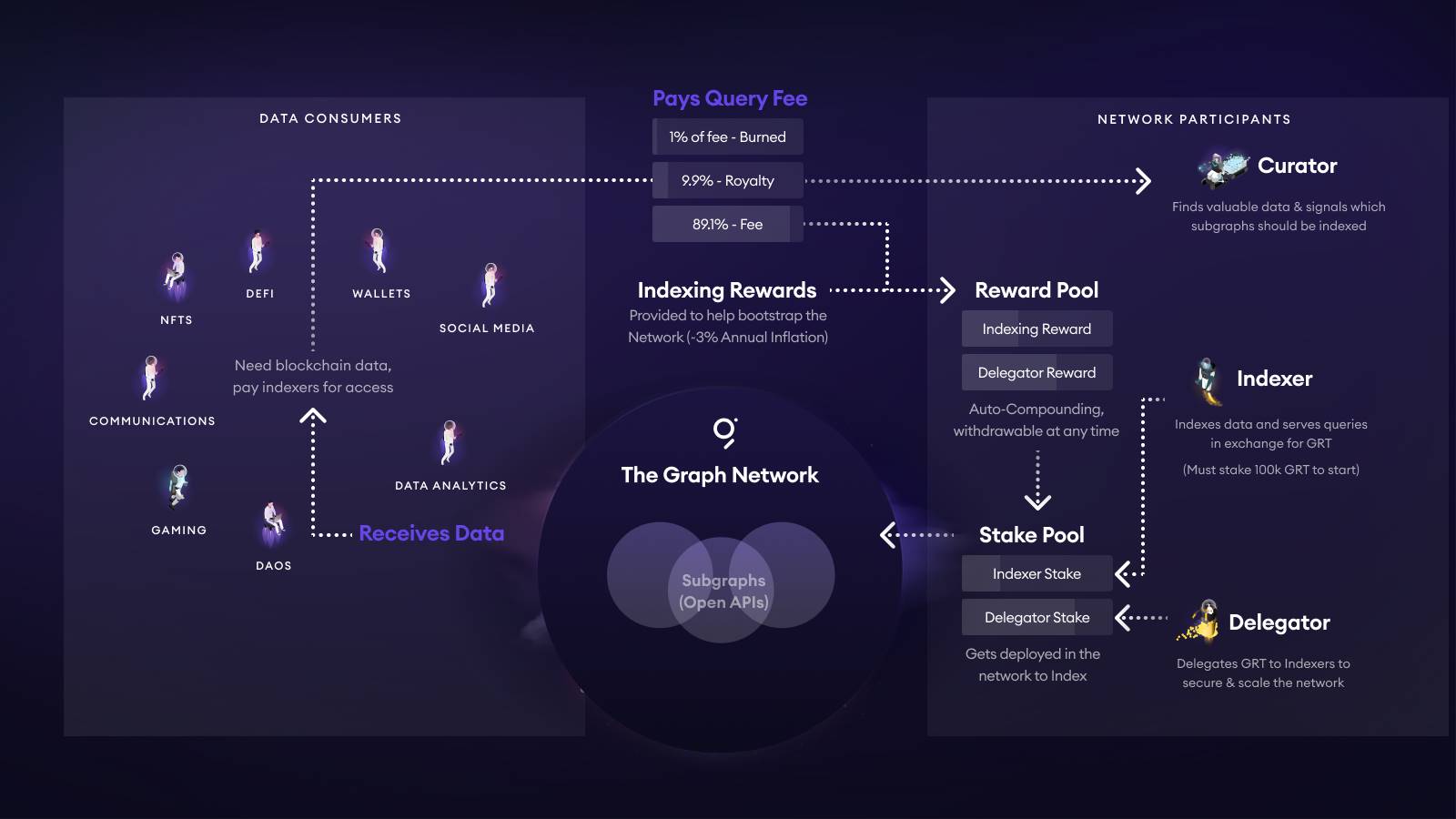
O modelo de preços da The Graph é inovador: as taxas de consulta e os incentivos estão integrados na tokenomics do GRT. Eis um resumo:
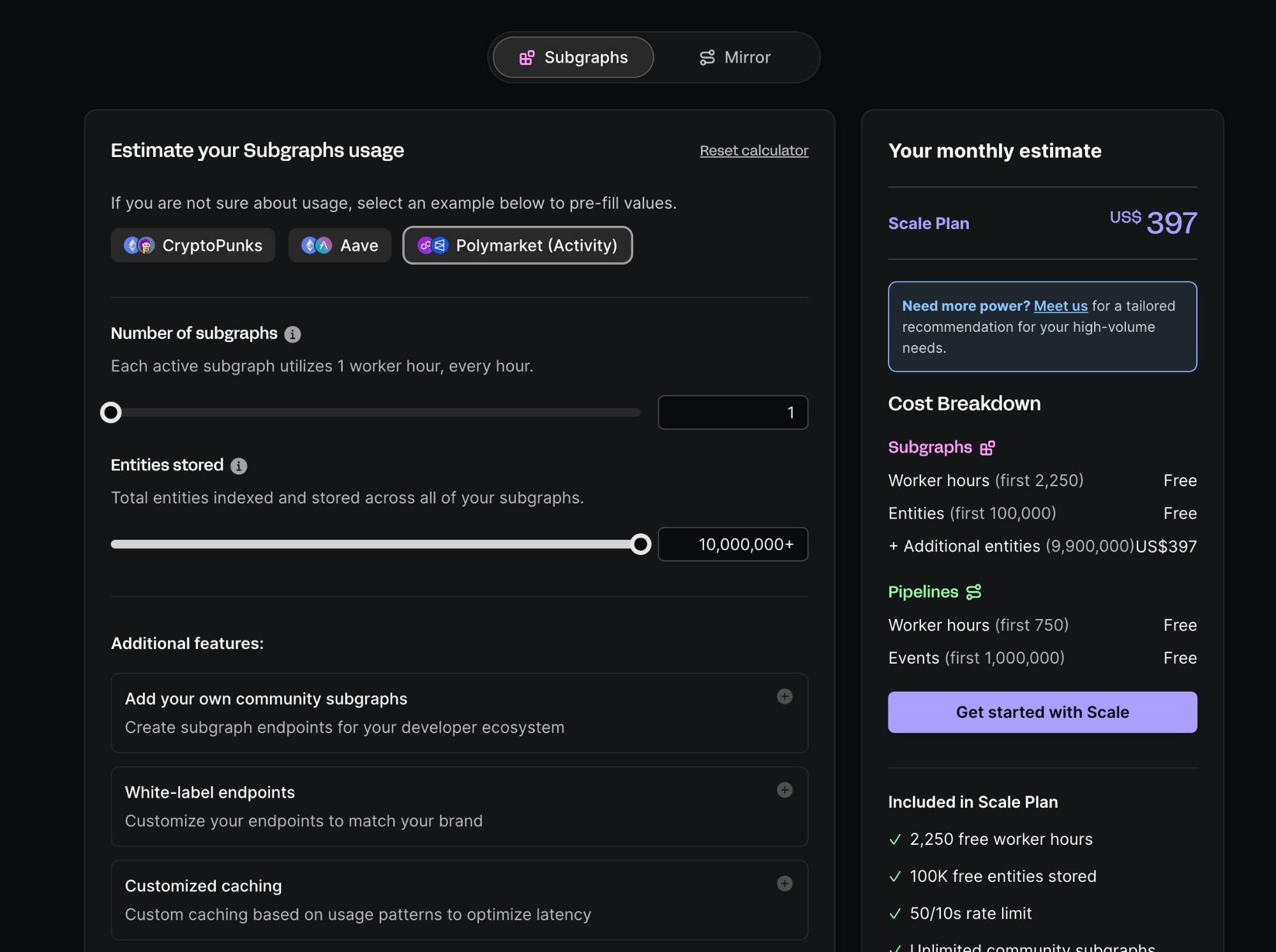
- Cada consulta a um SubGraph distribui as taxas da seguinte forma: 1% do GRT é queimado; 10% destina-se ao pool de curadores (geralmente developers); cerca de 89% é atribuído, via algoritmo, a Indexers e Delegators.
- Os Indexers devem fazer stake de pelo menos 100.000 GRT para participar e são penalizados por resultados incorretos. Os Delegators fazem stake de GRT junto dos Indexers para partilhar o pool dos 89% de recompensas.
- Os curadores (usualmente developers) sinalizam o seu SubGraph apostando GRT numa curva de bonding. Quanto maior o stake, mais recursos dos Indexers são atraídos. Recomendações comunitárias apontam para 5.000–10.000 GRT necessários para assegurar indexação contínua.
Taxas de Consulta:
Para consultar a The Graph, os developers registam-se, obtêm uma chave API e pré-compram GRT, sendo o custo debitado por pedido.
Taxas de Sinalização por Stake:
Para indexar SubGraphs, os developers têm de fazer stake de GRT para “sinalizar” valor, atraindo operadores. Só após atingir um determinado montante (ex: 10.000 GRT) é que os Indexers passam a indexar o SubGraph para produção.
Durante testes, é possível implementar SubGraphs gratuitamente com o staging operator da The Graph, mas essa solução não serve produção. Para produção, o SubGraph tem de ser publicado na rede, cabendo aos Indexers decidir, com base no staking sinalizado, se o querem indexar.
Porque É Que Developers (e Contabilistas) Fugiram do Modelo Baseado em Tokens
Na maioria dos projetos, o processo da The Graph é complexo. Comprar GRT é fácil para equipas Web3, mas o processo de curadoria é moroso e pouco previsível. Os problemas principais são:
- Incerteza: os developers têm dificuldade em saber quanto GRT devem fazer stake ou quanto tempo demorará até que os Indexers processem o seu SubGraph.
- Confusão contabilística: precificação baseada na tokenomics complica a gestão de custos, dificultando a classificação das despesas para empresas e respetivos contabilistas.
“Será Que a Centralização É Só Mais Fácil?”
Para a maioria dos developers, a Goldsky é, simplesmente, mais prática: preços transparentes, serviço imediato após pagamento e quase nenhuma incerteza. Isso levou a que a Web3 fique exposta pela dependência excessiva de um único fornecedor de indexação.
A lógica tokenómica do GRT na The Graph pode ser nobre, mas a complexidade afasta potenciais utilizadores e não deve recair sobre o utilizador final — a curadoria por staking, em particular, deveria ser escondida atrás de um interface de pagamento simples.
Não se trata apenas de opinião: Paul Razvan Berg, engenheiro de smart contracts e fundador da Sablier, criticou publicamente a experiência de publicação de SubGraph e do modelo de pagamento em GRT como bastante deficitária.
III. Soluções Atuais para Quebras de Indexadores de Dados
Como deve o ecossistema reagir a pontos únicos de falha na indexação de dados? Como acima discutido, os developers podem recorrer à The Graph, mas enfrentam as barreiras do staking em GRT e da curadoria para pagar o uso da API.
No universo EVM existem múltiplas alternativas à indexação de dados. Referências úteis: The State of EVM Indexing (Dune), o Overview da rindexer e este fio recente.
Este artigo não detalha a causa técnica do incidente Goldsky; de acordo com o relatório oficial, a Goldsky divulgou detalhes apenas a clientes empresariais. O relatório indica que o problema ocorreu ao gravar dados indexados na base de dados, com o acesso restabelecido só após intervenção da AWS.
Eis outras opções:
- ponder é uma ferramenta de indexação de dados simples e intuitiva, facilmente auto-hospedada em infraestrutura própria.
- local-first é uma filosofia de desenvolvimento que preconiza que DApps mantenham a usabilidade mesmo sem ligação à rede. Em blockchain, significa garantir boa experiência ao utilizador sempre que a ligação à chain esteja operacional, mesmo que os indexadores estejam offline.
Ponder: Indexação DIY (“Faça Você Mesmo”)
Porquê recomendar ponder?
- Sem lock-in de fornecedor: criado por developer independente, basta um endpoint Ethereum RPC e uma base de dados Postgres, sem necessidade de serviços de terceiros.
- Excelente experiência de desenvolvimento: construído em TypeScript e tirando partido da biblioteca Viem, ponder é bastante acessível (testado pelo autor).
- Desempenho de topo.
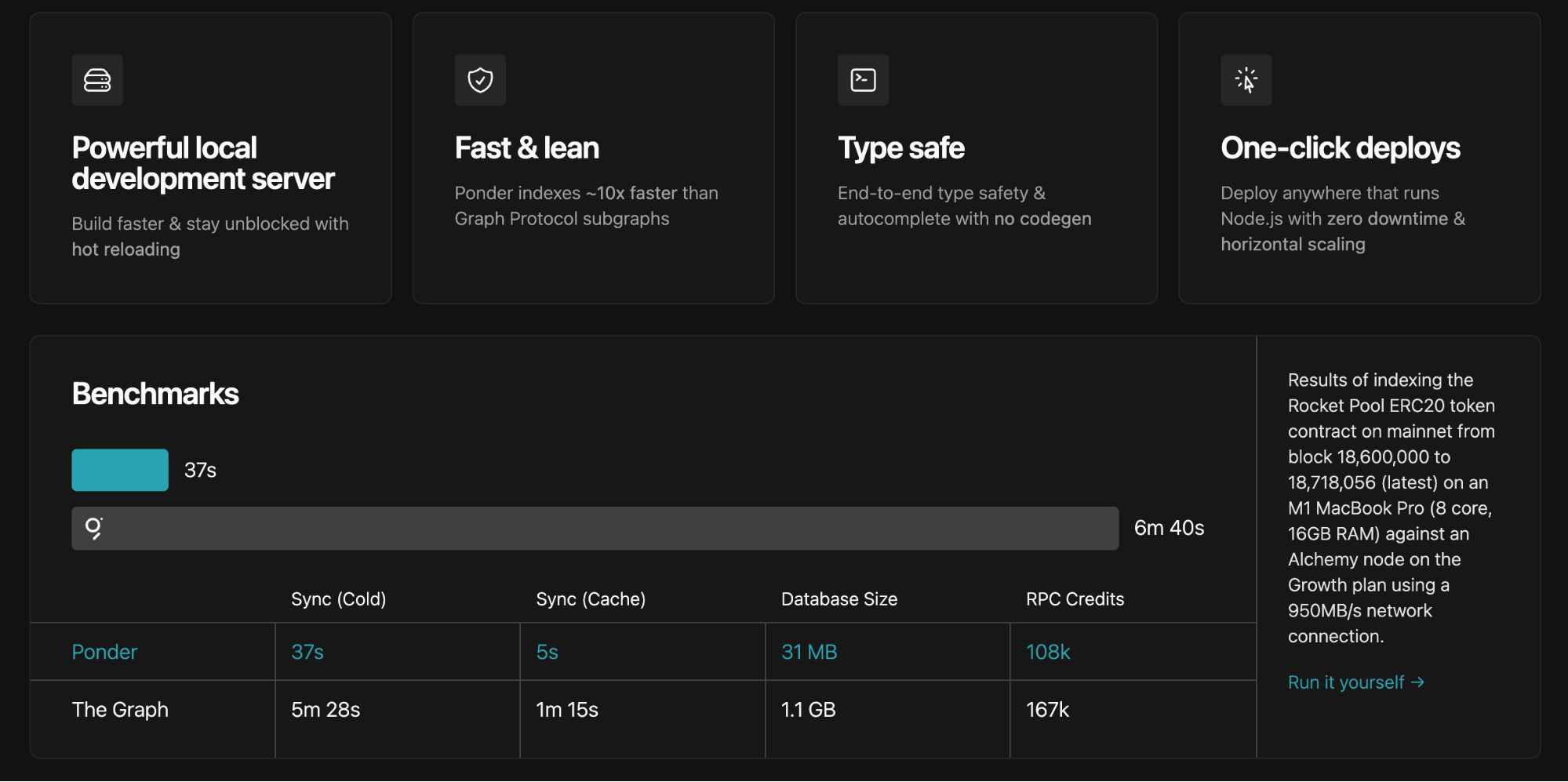
Há desvantagens: ponder está em rápida evolução, pelo que alterações podem afetar versões antigas. Para detalhes técnicos e boas práticas, consulte a documentação oficial.
Curiosamente, ponder começou recentemente a explorar uma estratégia comercial alinhada com a “teoria da separação” discutida anteriormente.
Resumindo: os bens públicos beneficiam todos, mas cobrar pelo seu uso pode excluir utilizadores marginais e reduzir o bem-estar global (não ótimo segundo Pareto). Tarifação diferenciada poderia maximizar o valor excedente, mas é cara e difícil de operacionalizar. A teoria da separação sugere cobrar apenas a um subgrupo homogéneo, deixando o restante público inalterado.
Na ponder, isto significa:
- A implementação requer conhecimentos técnicos — configurar endpoints RPC e bases de dados externas.
- A manutenção contínua pode ser exigente (p.ex., utilizar proxies para load balancing e garantir recuperação eficiente de dados). Pode não ser trivial para todos os developers.
- Disponibilizam agora uma beta de deployment automático via Marble, permitindo deployment one-click de código submetido à plataforma.
Assim, quem valoriza a conveniência paga pelo serviço na Marble, enquanto quem prefere auto-hospedagem mantém acesso livre ao ponder.
Ponder vs. Goldsky:
- Ferramentas verdadeiramente permissionless e auto-hospedadas como ponder são populares em projetos pequenos que querem autonomia e flexibilidade.
- Grandes projetos, com maiores exigências de performance, optam geralmente por serviços geridos como Goldsky, pela disponibilidade e redundância superiores.
Ambos os modelos comportam riscos. A quebra da Goldsky reforça a necessidade de cada developer manter o seu próprio indexador ponder como plano de contingência. Ao usar ponder, importa também garantir a integridade das respostas do endpoint RPC — recentemente, a safe reportou um incidente de falha do indexador devido a dados inválidos do RPC. Não existe prova cabal de que o incidente Goldsky tenha tido origem em questões RPC, mas é uma possibilidade a considerar.

O Paradigma de Desenvolvimento Local-First
Nos últimos anos, a abordagem local-first mereceu debate significativo. Fundamentalmente, propõe:
- Disponibilidade offline
- Colaboração multi-cliente
Muitas discussões técnicas local-first abordam CRDTs (Conflict-free Replicated Data Types) — estruturas especializadas para edição distribuída com resolução automática de conflitos. Em termos práticos, equivalem a pequenos protocolos de consenso que mantêm dados coerentes entre dispositivos.
No desenvolvimento blockchain, os requisitos podem ser flexibilizados: o objetivo é assegurar ao utilizador operações mínimas mesmo sem acesso aos indexadores backend, visto que a blockchain garante a consistência cross-cliente.
Assim, DApps local-first podem:
- Guardar localmente dados críticos — saldos, posições — garantindo ao utilizador sempre acesso ao último estado conhecido, mesmo se o indexador falhar.
- Degradar de forma progressiva — recolher dados essenciais diretamente do RPC sempre que os indexadores estejam fora, permitindo acesso parcial a dados on-chain em tempo real.
Esta abordagem aumenta substancialmente a robustez das aplicações. No cenário ideal, o melhor DApp local-first permitiria aos utilizadores correr um nó local e consultar dados recorrendo, por exemplo, ao TrueBlocks. Para leitura adicional sobre indexação descentralizada e local, consulte o fio Literalmente ninguém se preocupa com frontends e indexadores descentralizados.
IV. Conclusão
A interrupção de seis horas na Goldsky foi um verdadeiro alerta para o ecossistema Web3. Embora as blockchains sejam desenhadas para serem descentralizadas e resilientes, a maior parte dos projetos de aplicação mantém elevada dependência de infraestrutura centralizada — expondo o ecossistema a riscos sistémicos emergentes.
Este artigo demonstrou como a The Graph, apesar da notoriedade, enfrenta dificuldades na adoção devido à complexidade do modelo tokenómico GRT e à fricção técnica. Debatemos ainda estratégias para reforçar a resiliência da indexação de dados — incentivando o recurso a frameworks auto-hospedados como ponder como solução de backup e destacando o modelo comercial inovador da ponder. Por fim, explorámos o paradigma local-first, apelando a que os developers de DApps assegurem usabilidade mesmo quando os indexadores falham.
Cada vez mais, os developers Web3 reconhecem os pontos de falha únicos na indexação de dados como vulnerabilidade crítica. A GCC desafia a comunidade a priorizar este problema fundamental de infraestrutura e a experimentar indexadores de dados descentralizados ou frameworks que mantenham os frontends dos DApps operacionais, mesmo na ausência de indexadores online.
Aviso Legal:
- Republicação a partir do TechFlow. Os direitos de autor pertencem ao autor original, shew. Em caso de dúvida sobre esta republicação, contacte a equipa Gate Learn.
- Declaração de exoneração: as opiniões partilhadas neste artigo são exclusivamente do autor e não constituem aconselhamento de investimento.
- As traduções da Gate Learn não podem ser copiadas, distribuídas ou plagiadas sem atribuição explícita a Gate.com.
Artigos relacionados

Utilização de Bitcoin (BTC) em El Salvador - Análise do Estado Atual

O que é o Gate Pay?

O que é o BNB?

O que é o USDC?

O que é Coti? Tudo o que precisa saber sobre a COTI
